Evolution of a NetworkHub
[aws distributed-computing transitgateway networkhub In this blog post, we’ll talk about how a basic network setup has grown and changed over time. Just from a single VPC connecting to a data centre to a fully-fledged multi-regional hub and spoke architecture connecting multi-regional remote sites.
What the customer initially wanted?
The customer needed a solution to connect their remote sites, which were spread out from Australia to as far as Africa and Canada. These sites were quite remote and had limited internet connectivity. Consequently, they had to depend on satellite internet service providers like Starlink to establish connectivity.
what we proposed was a simple VPC connecting all remote sites via site-to-site VPN.
It’s always essential to consider as a prerequisite whether your customer gateway peer supports the default behaviour of the AWS side of the connection
Initial Design
The below figure illustrates the initial design

We could have just used a transit VPC and connected it to the regional data sites and VPCs via site to site VPN via VGW instead of TGW this would have necessitated highly available layer2 VPN appliances to be maintained by the client and a dedicated network engineer to look after it. Instance based routing gets costly when its tries to scale up and its constrained by the instance bandwith limitations.
Whereas TGW is a highly available and scalable managed services and it supports upto 50Gbs burst traffic out of the box .
Iteration of the Initial Design
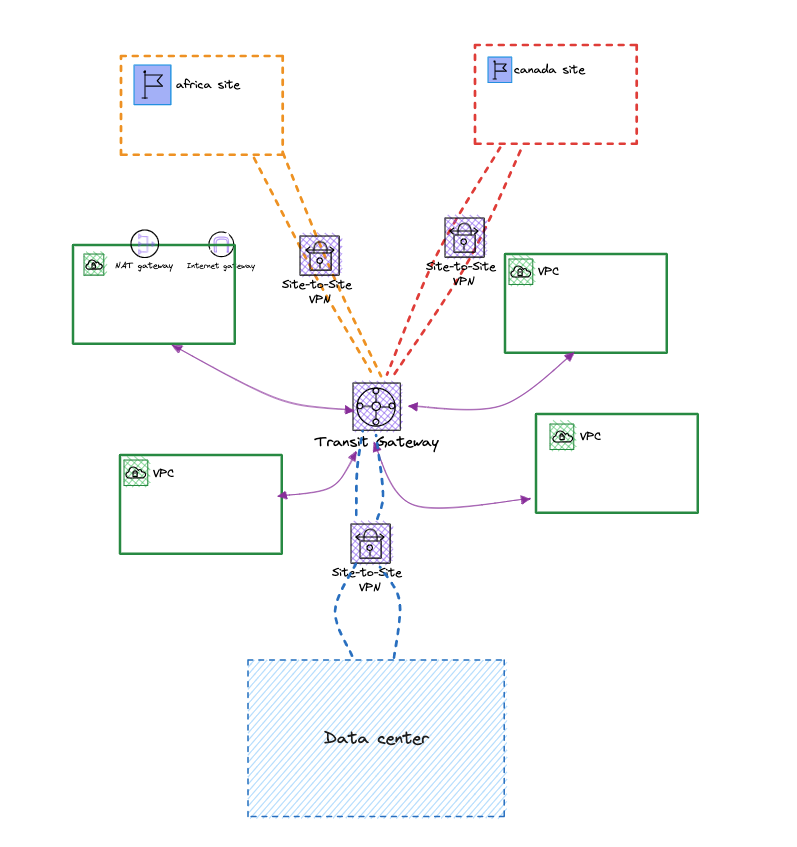
Transit Gateway was used to give connectivity between VPCs spread across accounts and the site-to-site connections terminated at the TGW instead of a virtual private gateway.
Since the remote sites are even further from the home VPC region and they rely on 3G/4G/satellite internet connectivity, we suggested they use AWS global accelerator on the VPNs to route traffic through the nearest AWS point of presence.
With the inclusion of the Global Accelerator, the design looked as shown below.
With the inclusion of GA
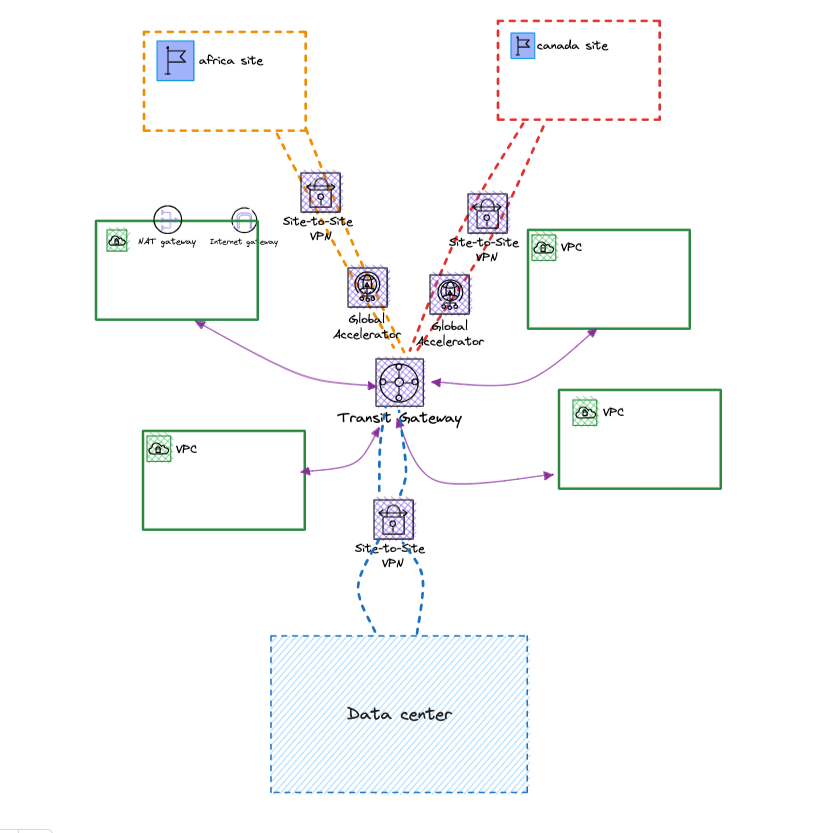
AWS Global Accelerator can enhance the performance of site-to-site connectivity by up to 60%, ensuring faster data transfers and reduced latency.
Imagine you’re a customer using a cloud service for important tasks. Just like anyone else, you wouldn’t want all your important services to rely solely on one cloud provider. That would be risky, as it could lead to a single point of failure. So, to avoid that, you’d prefer to distribute the risks by not depending entirely on one cloud vendor.
They sought the help of palo alto ( prisma cloud ) to provide a middle layer between the remote sites and the AWS side and also at the same time use the nearest point of presence provided by Palo Alto to stay closer to their remote sites.
You would have already guessed how the design would be transformed as you would see soon.
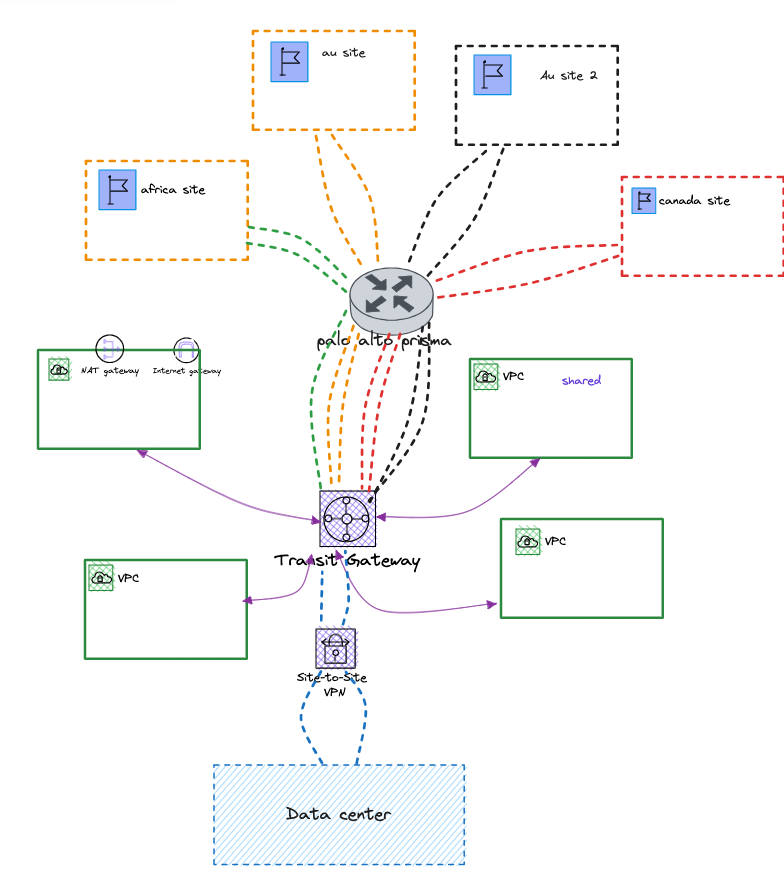
At this point in the design, we had successfully ensured high availability (meaning it could withstand any potential zonal failures) by using multiple availability zones and avoiding reliance on a single cloud vendor. However, there was still one concern that bothered the customer.
What if an AWS region or Palo Alto regional construct fails, will it pull down the rest of the services together with it ?
Simple answer is yes . It would inevitably pull the rest of it down and how would you circumvent it?
So, we came to a decision: to make use of AWS regions. This choice greatly enhances the architecture’s ability to handle faults and ensures overall stability. In this setup, each region will have its network hub, just like in the initial design, and we’ll maintain the same number of Virtual Private Clouds (VPCs) across AWS Accounts. All these network hubs will be interconnected in a mesh-like pattern. Each Site to site connection originating from Palo Alto Prisma will be terminated at each end of the regional network hubs as shown below.
Initially, every site-to-site VPN connection was rolled out to a single network hub as shown below
Redundant Site to Site terminating at a network hub
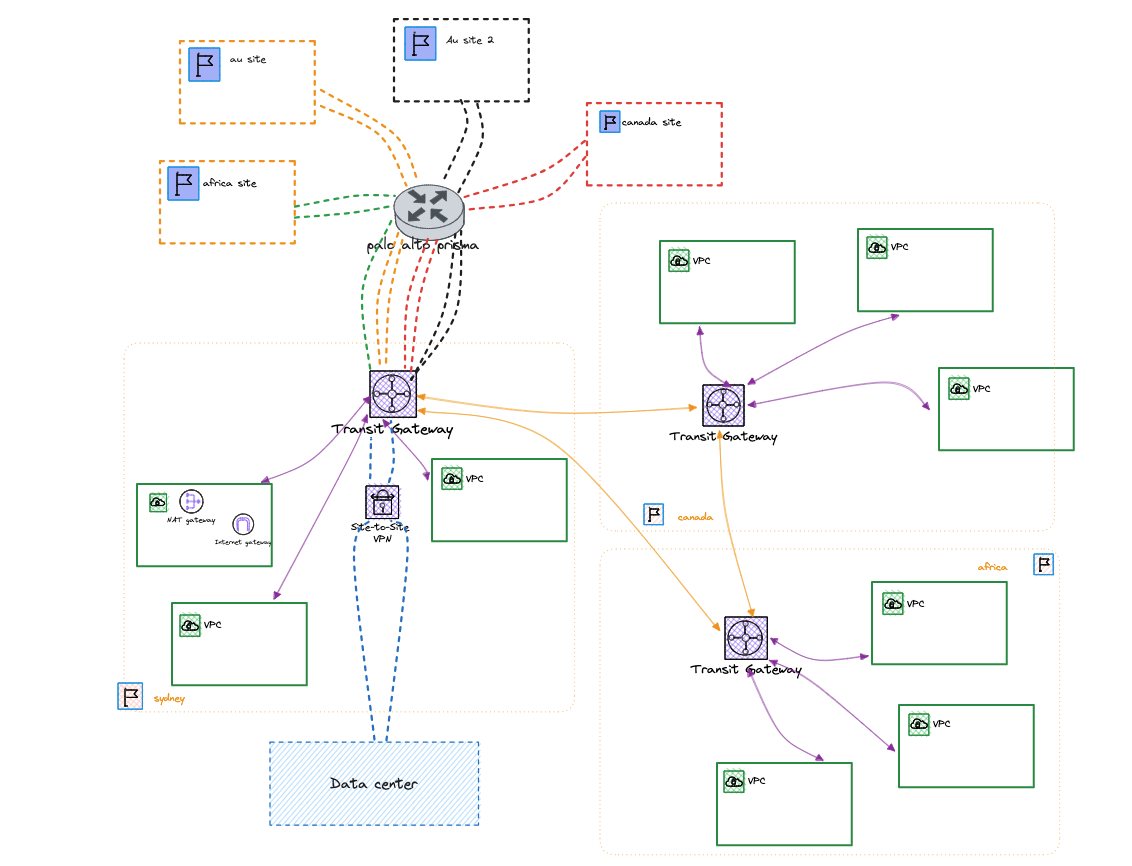
Then once the rest of the regional network hubs were ready those redundant connections made their way to their intended regional hub as shown below
Site to Site terminating at each regional hub
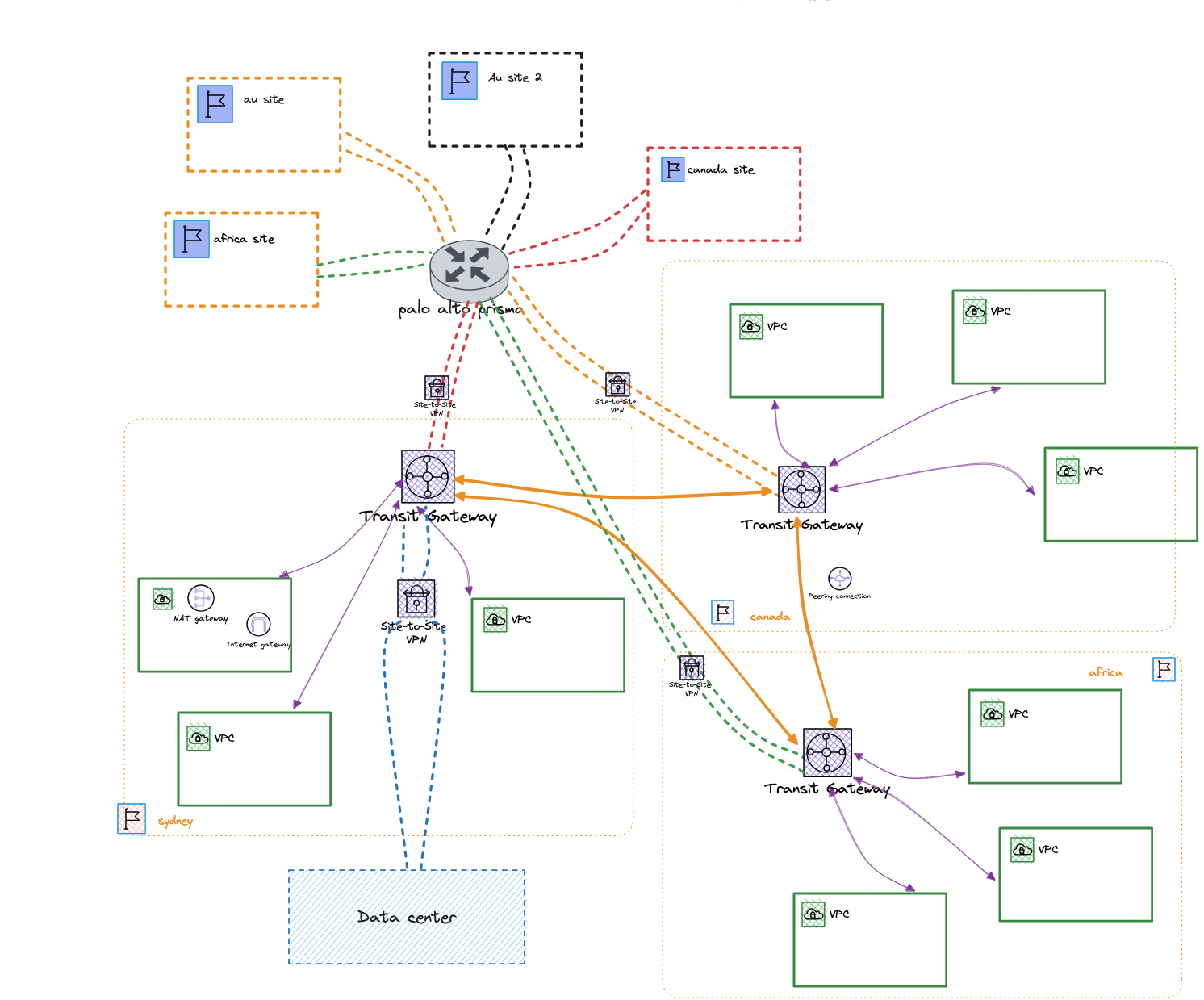
Reliability has been strengthened to withstand both zonal and regional failures effectively. Managed services such as TGW/Site-to-Site VPN, along with Prisma Cloud, significantly enhance availability, ensuring seamless service without disruptions
Implementation
AWS serverless network orchestrator was chosen as the automation tool for the multi-regional network hub implementation. The tool was deployed using the customisations for control tower from the master account. The orchestrator was seamless in its execution for applying attachments and associations against the TGW ( transit gateway) and its route tables. Even the peering between regional TGW was applied using the orchestrator.
As we were setting up the orchestrator on a brand-new AWS region, we encountered a situation where certain services were not yet accessible. This prevented us from fully utilizing the orchestrator’s complete range of features. To work around this, we chose to programmatically exclude those services by making changes to the code. This way, we could still proceed with the implementation without those specific features.
Due to security and cost optimisation considerations, an egress VPC for each regional network hub was introduced to direct all the outbound internet traffic from the regional spoke VPCs to go through it. In addition, interface endpoints with their own private hosted zones were implemented on the same egress VPC to be shared across the network hub. This keeps the traffic within the AWS network backbone without relying on the egress internet traffic and reduces the costs significantly.
Conclusion
In simpler terms, We added an extra layer of reliability to their cloud setup by bringing on another cloud provider between regional sites and AWS also opting in for AWS regional redundancy through a multi-regional network hub, making it more reliable, fault-tolerant and redundant. This way, if one part of the system fails, it doesn’t bring down everything else with it. It’s like having a backup plan for when things don’t go as expected. This design transformation helps ensure a smoother and safer cloud experience overall.